I hope that this posts and others in the series will be helpful to fellow conlangers. I've been using SIL's FLEx to keep track of my lexicon(s) for over a year now, and I've found it quite helpful. I hope to explain in more detail throughout this series the various features and how they can be used for conlanging. To start, though, you might be asking "What if I already have a lexicon in another format?" This first post in the series will hopefully help you overcome that obstacle.
Before we get to that, though, let me direct you to where you can obtain FLEx, for free (SIL's good like that, providing their software to the Linguistic community for free): http://www.sil.org/resources/software_fonts/flex
Once you've downloaded and installed FLEx, and created your project, you're ready to import your lexicon!
When you first open FLEx, you should see a screen like this (yours shouldn't have any previous projects, of course):
As you might have guessed, choose "Create a new project". Now you should see this:
You'll want to type in the name of your project, probably the name of your conlang, though you could always call it "Joe's Super-Awesome-Never-Before-Seen Basket Full of Amazingness", if you felt so inclined. I'm going to call mine "Sample Projectish":
Then click OK. But you're not done yet! Now you'll get this:
It's up to you, of course, but one feature of FLEx is that you can also categorize and take notes regarding cultural aspects. I've gone ahead and said OK to the Enhanced OCM for each of my projects. In a future post, I'll try to explain how some of that works, too. But for now, let's get into the program itself. Once you've made your choice regarding whether to include OCM or not, you should have a shiney new FLEx project open, that looks like this:
You're now ready to import whatever lexicon you already have. To do so, in the top left hand corner, click File>Import, which should pull up this list:
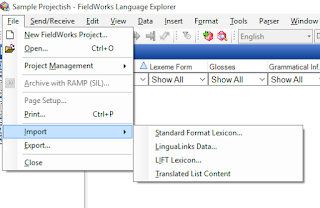
Unfortunately, I'm not familiar with options other than Standard Format Lexicon. I probably should explore a bit more and figure things out, but for now, I'll share what I know, which involves importing data from an Excel chart. So, if I were you, I would go ahead and click on Standard Format Lexicon. This opens the following screen in the middle of your FLEx project:
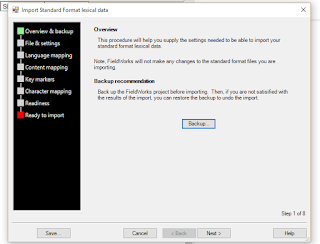
It's recommended that you backup the project before continuing, but since you have nothing there, so far, I wouldn't worry about it too much. The next screen is where you want to worry. You have the option of choosing a file to use. Unfortunately, I haven't had much success with simply importing a straight up Excel file. But what has worked has been copying and pasting excel data into a plaintext file (.txt). Before doing that, however, you'll need to make sure you have appropriate markers in place, so that your data will go to the correct place in FLEx. This may depend on how complex your existing lexicon is. If you simply have the word in your conlang and a gloss in your native language, you only need to know the two markers \lx (which puts the word in your conlang into the 'Lexeme Form' column) and \ge (this stands for 'Gloss: English', so it will be different if your glosses are in your native language, but it shouldn't make too much of a difference - this marker will send your glosses to the 'Gloss' column).
A list of mapping markers is available on page 4 of the document. You can include things such as part of speech, example sentences, and so on.
Using the appropriate markers, I would insert a column before each section, write in the appropriate marker into the first cell, and copy and paste it into the rest of the column. That should look something like this (These examples are from Omaya, one of my conlangs):
From this point, it gets a little bit labor intensive. If you have a huge lexicon, I'm sorry (the first time I did this was with a lexicon of over 3000 words)! There may be an easier way to do it, but I haven't figured it out yet (or maybe I did with that first time, but it's been a while and I've quite forgotten!).
The next step is to copy and paste your Excel data into a plaintext file. Alternatively, you could simply save it as a plain text file (.txt). Now the laborious part: I haven't been able to get the import to work without having the \lx word directly above the \ge gloss! That is I have had to go in and press enter before every single instance of \lx! That is, given a text file that has the following:
\ge "all, every" \lx la
\ge and \lx h'
\ge animal \lx inwalu
\ge appearance \lx holu
\ge arrow \lx arwu
\ge ask \lx se
I have had to make it look like this, instead:
\ge "all, every"
\lx la
\ge and
\lx h'
\ge animal
\lx inwalu
\ge appearance
\lx holu
\ge arrow
\lx arwu
\ge ask
\lx se
Once you've done that horribly tedious, intensive part, things are much easier. Save the .txt file where you can find it again, and return to FLEx. Click 'Next' after the initial import screen, and you should see one that looks like this:
Click on the square with the ellipsis (...) and find the appropriate file. Since it's a text file, you'll have to choose the scrolldown option 'All Files':
Find your Text file, select it, then click 'Next' (you could really go ahead and click 'Finish', because this should work at this point, but you might want to make sure the markers you've used show up in the 'Key Markers' screen).
On the 'Content Mapping' page, and the 'Key markers' page, make sure all of the markers you're using show up, like so:
And the next page, like so:
The next page won't have anything on it, so you might as well go ahead and click 'Finish'. You should now see an option to 'Generate Report', like this:
Go ahead and click on that (you have no other option, anyway), and you should be taken to a webpage that gives you either the correct number of items that you have in your lexicon, or an error message. If it's an error, you might have to adjust some settings, and I don't necessarily know what they are. It should be fine, though, and you should see this:
If this is what you see and everything is in order, go back into FLEx and click 'Next', then 'Finish' (if you don't want to see the same report again, click on the checkmark in the box that reads 'Display final report' before you click 'Finish'). You should see a processing bar, then, voila! your FLEx project is filled with all your beautiful words!
I hope this is helpful to all my fellow conlangers out there! If you have any questions or, even better, if you find a way to make this process easier, let me know in the comments!
Next post, I'll go over some of the basic features of FLEx, including how to enter new words, the fields in an entry, etc. Or maybe it would be better to do a general overview first. I'll think about it and get back to you soon!
EDIT: J Diego Suárez Hernandez provides this tip:
There is a trivial way of adding newlines (~ pressing 'enter') before every \lx with many text editors.
If you are using Notepad++ (a free lightweight text editor similar to Windows' Notepad but with tons of useful features, like being able to edit several documents in tabs on the same window), you have to:
- copy your text (or table) to it,
- go to 'Replace' in the 'Search' menu (or press its keyboard shortcut: Ctrl+H)
- Search for " \lx" (space, backslash, l, x; without the quotes)
- Write "\n\lx "(backslash, n, backslash, l, x)
- Press the "Replace" all button.
This will replace every occurrence of a space followed by \lx with a newline (represented as "\n") and "\lx" at once.
This can also be done in other editors. For instance, OpenOffice Writer and LibreOffice Writer let you do the same but you have to mark "regular expresions" under the "more options" tab in the search&replace dialogue.














